Abstract
Despite advances in audio-driven avatar generation, existing methods often model one side of conversation or rely on explicit role switching, failing to capture truly interactive conversational dynamics. To this end, we introduce CoTalker, a two-stage audio-driven framework that synthesizes interactive conversational head avatars from a reference portrait image and multimodal conversational signals. The framework integrates a diffusion-based motion generator with a GAN-based avatar renderer, enabling expressive conversational motion prediction and high-fidelity video rendering. A novel state guider is introduced to fuse audio–visual cues and model latent interaction patterns in real conversational scenarios. Furthermore, a progressive training strategy is employed to leverage single-role motion priors before dyadic finetuning, enhancing the model's ability to generate semantically aligned speaking motions, diverse listener responses, and seamless role transitions without explicit role assignment. Extensive experiments demonstrate that CoTalker outperforms state-of-the-art methods in producing photo-realistic and context-aware interactive conversational avatars.
Pipeline
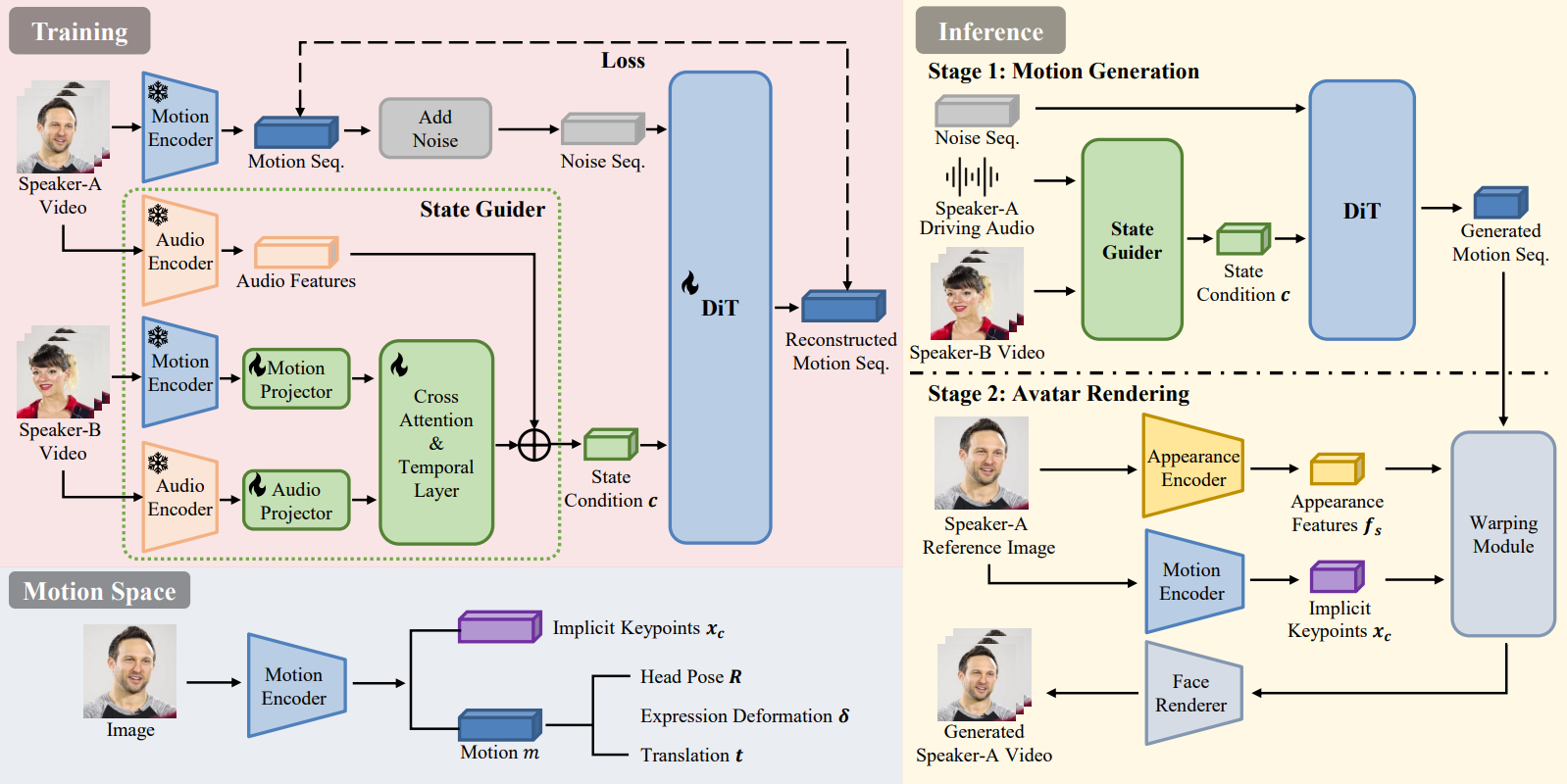
Overview of CoTalker. The framework is built upon an latent motion space that extracts canonical 3D impliciy keypoints and identity-agnostic motion representations. Given a reference image, driving audio, as well as the interlocutor’s audio-visual signals, CoTalker synthesizes context-aware head motions that reflect both verbal and non-verbal conversational cues and renders high-fidelity video frames in a dyadic conversation.